Supervised learning is the most commonly used type of machine learning in real-world systems. It is often the first approach organizations adopt because it is structured, measurable, and easier to validate compared to other learning methods.
At a high level, supervised learning teaches a system by showing it examples along with the correct answers. Over time, the system learns how inputs relate to outputs and uses that knowledge to make predictions on new data.
What Is Supervised Learning?
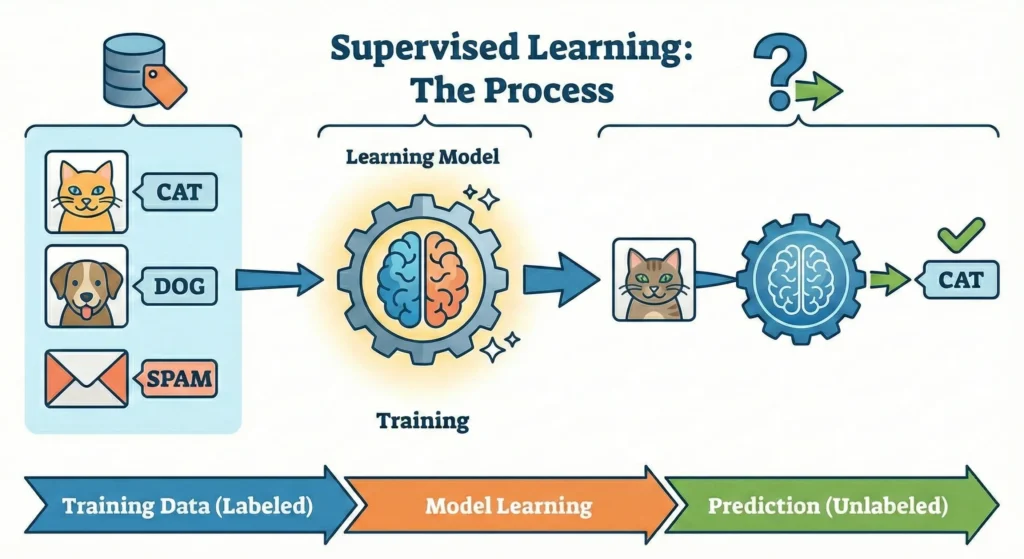
Supervised learning is a machine learning approach where each training example includes two specific parts:
- Input data: (for example, an email or an image)
- A Label: (the correct answer, such as “spam” or “not spam”)
The model’s job is to learn the relationship between inputs and labels so it can predict the correct label for new, unseen data.
A simple way to think about it: Supervised learning is learning with an answer key. The teacher (the data) provides both the questions and the answers, and the student (the model) studies them to pass a future exam.
How Supervised Learning Works (Step by Step)
While the underlying math can be complex, the workflow is straightforward.
- Labeled data is collected: Historical data containing known outcomes is gathered.
- Data is split: The data is divided into a Training Set (to teach the model) and a Testing Set (to evaluate performance).
- The model is trained: It processes the training data to find patterns linking inputs to outputs.
- Performance is evaluated: The model is tested on the “Testing Set” to see if it can accurately predict answers it hasn’t seen before.
- Adjustments are made: Errors are measured, and the model is refined to reduce mistakes.
- Production: Once accurate, the model is deployed to predict outcomes for completely new inputs.
This feedback-driven process is what allows supervised learning models to improve over time.
The Two Main Types of Supervised Learning Problems
Supervised learning is typically used to solve two distinct problem types: Classification and Regression.
1. Classification
Classification problems involve predicting a specific category or class. The output belongs to a fixed set of possible labels.
Common examples include:
- Spam vs. Non-spam: Identifying unwanted emails.
- Fraud Detection: Flagging fraudulent vs. legitimate transactions.
- Image Recognition: Distinguishing between a cat and a dog.
2. Regression
Regression problems involve predicting a continuous numerical value. Here, the output is a number rather than a category.
Common examples include:
- House Price Prediction: Estimating real estate value based on features like size and location.
- Sales Forecasting: Predicting future revenue based on past performance.
- Demand Estimation: Calculating how much inventory will be needed next month.
Quick Check: If you are asking “What kind is this?”, it is Classification. If you are asking “How much?”, it is Regression.
Real-World Examples of Supervised Learning
Supervised learning is already embedded in many everyday systems:
- Email Spam Filters: These systems learn from millions of labeled emails to identify and segregate unwanted messages.
- Image Recognition: Social media platforms and phones use models trained on labeled images to recognize faces or objects.
- Fraud Detection Systems: Banks analyze millions of past transactions labeled as “fraud” or “safe” to instantly spot suspicious patterns.
- Price Prediction Models: Travel sites use historical pricing data to estimate whether flight prices will go up or down.
What connects all these examples is the availability of labeled historical data.
Why Supervised Learning Is So Widely Used
Supervised learning remains popular because it offers several practical advantages:
- Measurable Results: You can easily calculate exactly how accurate the model is (e.g., “98% accuracy”).
- Predictability: Models behave in a way that aligns with the historical data they were fed.
- Easier Validation: Performance can be monitored and validated over time.
- Business Alignment: It aligns well with business use cases that already generate labeled data (like sales records or customer logs).
For many organizations, supervised learning provides the most reliable path from raw data to actionable decisions.
Limitations of Supervised Learning
Despite its strengths, supervised learning has important constraints that must be managed:
- Labeled Data is Expensive: Creating high-quality labels often requires significant human effort and domain expertise.
- No Discovery: Models learn only what they are shown; they do not automatically discover new patterns or categories outside of their training data.
- Data Quality Dependency: Biased or incorrect labels lead to biased or incorrect predictions. If the “answer key” is wrong, the model will be wrong.
When Supervised Learning Is the Right Choice
Supervised learning works best when:
- The problem is clearly defined.
- The desired output is known.
- Historical labeled data exists.
- Accuracy and reliability are more important than discovering new patterns.
It is especially effective in stable environments where patterns do not change rapidly.
Key Takeaways
- Supervised learning uses labeled data to learn.
- It is used primarily for classification (categories) and regression (numbers).
- It powers many real-world applications like spam filters and price predictors.
- Its success depends heavily on the quality of your data labels.
Understanding supervised learning gives you a strong foundation for exploring more advanced machine learning techniques.
Frequently Asked Questions
Supervised learning is a type of machine learning where a model learns from labeled training data. Think of it like a student learning from a teacher who provides an “answer key.” The model analyzes the input data and the correct answers to learn patterns, allowing it to predict outcomes for new, unseen data.
The two main types are Classification and Regression.
Classification predicts a category (e.g., Is this email “spam” or “not spam”?).
Regression predicts a numerical value (e.g., What will the price of this house be next year?).
The main difference lies in the data used. Supervised learning uses labeled data (inputs paired with correct outputs) to train the model. Unsupervised learning uses unlabeled data and lets the model find hidden patterns or structures on its own without a pre-defined answer key.
Supervised learning is used in many everyday technologies, including:
Email Spam Filters: Classifying emails as junk or inbox.
Face Recognition: unlocking phones by recognizing facial features.
Credit Scoring: Predicting if a loan applicant is low or high risk.
Weather Forecasting: Predicting temperature based on historical data.
Labeled data acts as the ground truth or “teacher” for the model. Without accurate labels (the correct answers), the model cannot verify its predictions or adjust its internal parameters to improve accuracy. The quality of the supervision depends entirely on the accuracy of these labels.
Comments