Artificial intelligence systems have traditionally been built to operate on a single type of data. Language models processed text, computer vision models analyzed images, speech models handled audio, and video systems focused on temporal signals. While each of these approaches delivered strong results within narrow domains, they failed to reflect how information exists in the real world—where meaning is almost always distributed across multiple modalities.
Multimodal AI addresses this limitation by enabling models to process, align, and reason across text, images, audio, video, and other data types simultaneously. Rather than treating each modality as a separate problem, multimodal systems integrate them into a unified representation, allowing AI to understand context in a way that more closely resembles human perception.
In 2025, multimodal AI has moved from experimental research into production-grade systems powering enterprise platforms, AI agents, retrieval-augmented generation (RAG), robotics, and advanced analytics. Understanding what multimodal AI is—and how it works—has become essential for anyone building or deploying modern AI systems.
Defining Multimodal AI
Multimodal AI refers to machine learning systems that can ingest, interpret, and reason over multiple data modalities within a single model or tightly integrated architecture. A modality represents a specific form of data, such as written language, visual information, sound, video, or structured sensor signals.
A multimodal system does not simply process these inputs independently. Instead, it aligns them into a shared semantic space where relationships across modalities can be learned and exploited. This allows the model to answer questions that require cross-modal understanding, such as explaining a chart using text, summarizing a video using language, or interpreting spoken instructions in the context of a visual interface.
This integration marks a fundamental shift from pipeline-based AI—where multiple specialized models are chained together—toward unified reasoning systems capable of holistic understanding. Multimodal AI enables models to reason across text, images, audio, and video. For a deeper technical breakdown of architectures, models, and real-world use cases, refer to our Multimodal AI guide.
Why Traditional AI Models Fall Short
Single-modality AI systems are inherently constrained by the type of data they can access. A text-only language model cannot interpret diagrams, screenshots, or handwritten forms. A vision model can detect objects in an image but lacks the linguistic reasoning needed to explain what those objects represent in context. Audio models can transcribe speech but struggle to connect spoken content with visuals or documents.
In real-world environments, information rarely exists in isolation. Business documents contain text, tables, charts, and scanned images. Meetings involve audio, video, shared screens, and written notes. User interfaces combine visual layout, icons, text labels, and interaction flows.
Multimodal AI overcomes these limitations by allowing models to reason across these combined inputs, eliminating the fragmentation that previously limited automation and intelligence.
How Multimodal AI Works at a High Level
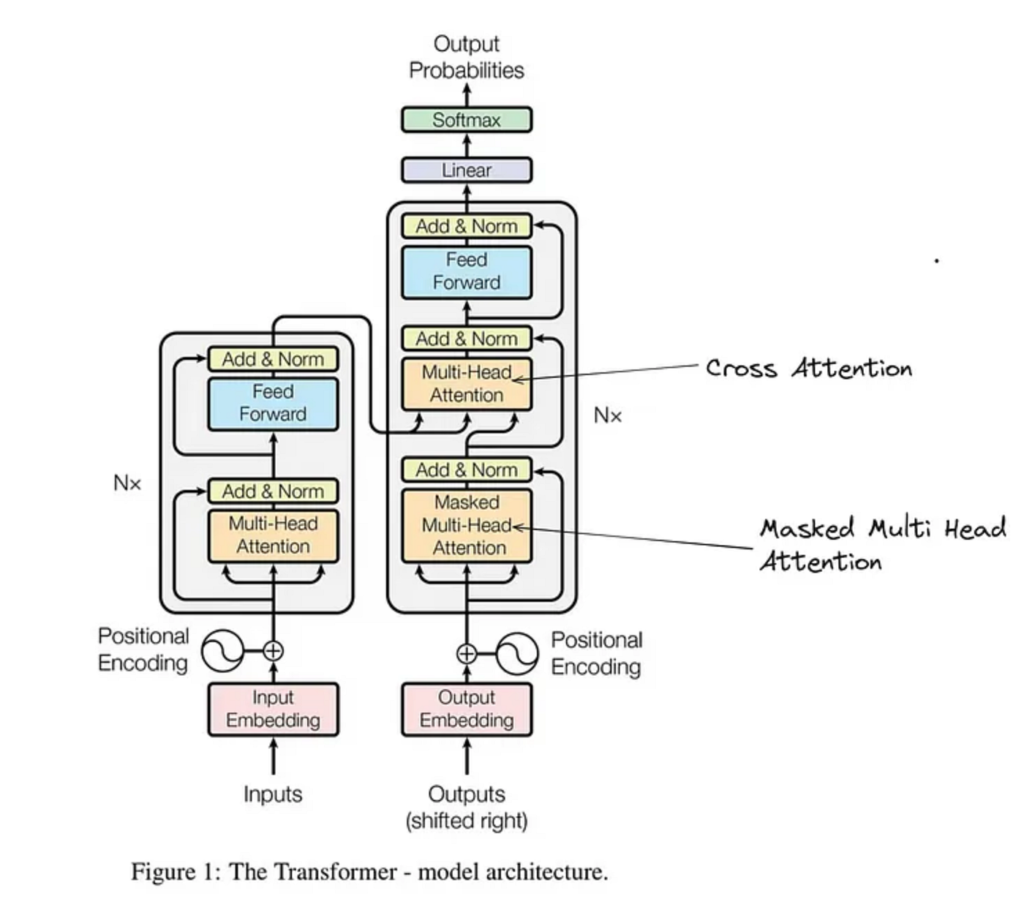
Although multimodal models appear simple at the interface level—often responding to a single natural language prompt—the internal architecture is significantly more complex.
Each modality is first processed by a modality-specific encoder. Text inputs are tokenized and embedded using transformer-based language encoders. Images are processed using vision encoders such as convolutional neural networks or vision transformers that extract spatial features. Audio inputs are converted into spectrograms and encoded into frequency-domain representations. Video inputs add a temporal dimension, requiring models to understand how visual information evolves over time.
These encoded representations are then projected into a shared latent embedding space. This shared space is what allows the model to associate concepts across modalities—for example, linking the word “invoice” to an image of a receipt or a scanned document.
Fusion occurs through attention mechanisms, most commonly cross-attention, which allows the model to reference information from one modality while reasoning about another. The final reasoning and generation step is typically handled by a large language model acting as a decoder, synthesizing all signals into a coherent response.
Core Modalities Used in Multimodal Systems
Modern multimodal AI systems commonly integrate several key data types.
Text remains the primary reasoning and instruction modality, serving as both input and output. Images provide spatial and visual context, enabling tasks such as document analysis, chart interpretation, screenshot understanding, and object recognition. Audio introduces speech and acoustic information, supporting transcription, intent detection, and sound classification. Video adds temporal understanding, allowing models to analyze actions, sequences, and events across time.
More advanced systems also incorporate 3D data and sensor signals, which are essential for robotics, autonomous systems, and industrial applications. The ability to unify these modalities is what enables multimodal AI to operate effectively in complex, real-world environments.
The Evolution of Multimodal AI Models
Early multimodal systems were limited to narrow tasks such as image captioning or visual question answering. These systems relied on loosely coupled components and lacked deep cross-modal reasoning.
The first major breakthrough came with contrastive learning approaches that aligned text and image embeddings into a shared space. This demonstrated that models could learn meaningful relationships across modalities at scale. The rise of transformer architectures and vision transformers further accelerated progress by providing a flexible foundation for multimodal fusion.
The current generation of multimodal AI integrates vision, audio, and video encoders directly into large language models. This architectural shift transformed LLMs into general-purpose reasoning engines capable of understanding and generating responses grounded in multiple modalities. As a result, modern systems can interpret documents, explain visuals, reason over videos, and interact with complex interfaces using a single unified model.
Why Multimodal AI Is Critical for Modern Applications
Multimodal AI has become essential because most meaningful data is inherently multimodal. Enterprises deal with documents that mix text, visuals, and structure. Customer interactions involve voice, chat, and screen content. Industrial systems generate sensor data alongside logs and video feeds.
By enabling unified reasoning across these inputs, multimodal AI unlocks automation opportunities that were previously impractical. It allows AI systems to process unstructured data more accurately, reduce manual intervention, and deliver insights that are grounded in full contextual understanding rather than partial signals.
This capability is especially important for AI agents, which must observe, interpret, and act within dynamic environments. Without multimodality, agents remain blind to large portions of the context they operate in.
Multimodal AI vs. Traditional Pipelines
Before multimodal AI, handling multiple data types required complex pipelines composed of independent models. An image would be processed by a vision model, converted into text, passed to a language model, and then combined with other outputs using custom logic. These pipelines were fragile, difficult to scale, and prone to error propagation.
Multimodal AI replaces this approach with end-to-end reasoning, where all modalities are considered jointly within the same model or tightly coupled architecture. This not only improves accuracy but also simplifies system design, reduces latency, and enhances maintainability.
The Role of Multimodal AI in 2026 and Beyond
Multimodal AI is rapidly becoming the default foundation for intelligent systems. It underpins advanced RAG architectures, enterprise document intelligence, conversational agents, robotics perception, and autonomous workflows. As models continue to improve in efficiency and alignment, multimodal reasoning will expand to real-time environments and on-device deployments.
The long-term trajectory points toward unified foundation models that seamlessly integrate perception, reasoning, memory, and action. Multimodal AI is not a feature layered on top of language models—it is the architectural shift that enables the next generation of AI capabilities.
FAQs
Multimodal AI is a type of artificial intelligence that can process and reason across multiple data types—such as text, images, audio, and video—within a unified model or architecture.
Traditional AI models operate on a single modality, such as text or images. Multimodal AI integrates multiple modalities, allowing richer contextual understanding and cross-modal reasoning.
The most common modalities include text, images, audio, and video. Advanced systems may also process 3D data, sensor signals, time-series data, and UI screenshots.
Multimodal models use modality-specific encoders to process each input type, align them in a shared embedding space, and apply cross-attention mechanisms for unified reasoning.
Enterprises work with documents, dashboards, videos, audio recordings, and visual interfaces. Multimodal AI enables automation and analysis across all these formats in a single system.
Yes. Modern AI agents rely on multimodal understanding to interpret documents, screenshots, interfaces, voice inputs, and environmental signals while performing real-world tasks.
Typical use cases include document intelligence, visual question answering, multimodal RAG, meeting analysis, robotics perception, healthcare imaging, and visual search.
Challenges include higher compute costs, cross-modal hallucinations, long-video reasoning limitations, data quality issues, and ethical concerns around visual and audio data.
Comments